Learning Kotlin: String Templates
- The code being referenced.
- This is the 6th post in a multipart series.
If you want to read more, see our series index
The purpose of this lesson is to show off string templating and the Koan starts with some interesting examples
fun example1(a: Any, b: Any) =
"This is some text in which variables ($a, $b) appear."
fun example2(a: Any, b: Any) =
"You can write it in a Java way as well. Like this: " + a + ", " + b + "!"
fun example3(c: Boolean, x: Int, y: Int) = "Any expression can be used: ${if (c) x else y}"
If you are used to string templates from C# and JavaScript this should be fairly simple to understand.
The fourth example is interesting
fun example4() =
"""
You can use raw strings to write multiline text.
There is no escaping here, so raw strings are useful for writing regex patterns,
you don't need to escape a backslash by a backslash.
String template entries (${42}) are allowed here.
"""
This brought up something I've never heard of, raw strings. Raw strings seem to be the Python way of saying a Verbatim string... which I didn't know was the official term.
The actual Koan here is about converting this fun getPattern() = """\d{2}\.\d{2}\.\d{4}""" to a different regular expression, using a string template:
fun task5(): String = """\d{2}\s$month\s\d{4}"""
It isn't that interesting and really, if you don't know regular expressions this could be tougher than it needs be.
Learning Kotlin: Lambdas
- The code being referenced.
- This is the 5th post in a multipart series.
If you want to read more, see our series index
So following C#, Kotlin has Lambda support with the change if => becoming -> and the Koan starts with some nice examples at the start:
fun example() {
val sum = { x: Int, y: Int -> x + y }
val square: (Int) -> Int = { x -> x * x }
sum(1, square(2)) == 5
}
Basically, though, the code that needs to be done is to check a collection if all items are even, which is easily done with:
fun task4(collection: Collection): Boolean = collection.any({item -> item % 2 == 0})
Learning Kotlin: Default values
- Code for the 4th Koan can be found here.
- This is the 4th post in a multipart series.
If you want to read more, see our series index
Previously we covered Named Arguments and this is a small continuation from it, we start with a simple function fun foo(name: String): String = todoTask3() and we need to have it call a single Java function and to provide it with default values which ultimately looks like this:
fun foo(name: String, number: Int = 42, toUpperCase: Boolean = false): String = JavaCode3().foo(name, number, toUpperCase)
Learning Kotlin: Named Arguments
- Code for the 3rd Koan can be found here.
- This is the 3rd post in a multipart series.
If you want to read more, see our series index
On to our third exercise and definitely, the difficulty curve has lowered again (or should it be steep) as we have a simple lesson - how to use named arguments.
Not only is an example for it provided for how named arguments work:
fun usage() {
// named arguments
bar(1, b = false)
}
We also get an example of default values for arguments
fun bar(i: Int, s: String = "", b: Boolean = true) {}
The problem we need to solve itself is simple too,
Print out the collection contents surrounded by curly braces using the library function 'joinToString'. Specify only 'prefix' and 'postfix' arguments.
Which has this answer:
fun task2(collection: Collection): String {
return collection.joinToString(prefix = "{", postfix = "}")
}
Not much to add to this lesson unfortunately.
Learning Kotlin: Java To Kotlin Converter
The second Koan is meant as an exercise of the IDE and is targeted at those moving from Java, as such this was a mixed bag for me.
The goal is to get a Kotlin version of Java code by letting the IDE do the conversion, but I decided to tackle it myself.
Initially, I thought I needed to do the entire file and not just the task function. So, what does the entire code look like when changed?
package i_introduction._1_Java_To_Kotlin_Converter;
import util.JavaCode;
import java.util.Collection;
import java.util.Iterator;
public class JavaCode1 extends JavaCode {
public String task1(Collection<Integer> collection) {
StringBuilder sb = new StringBuilder();
sb.append("{");
Iterator<Integer> iterator = collection.iterator();
while (iterator.hasNext()) {
Integer element = iterator.next();
sb.append(element);
if (iterator.hasNext()) {
sb.append(", ");
}
}
sb.append("}");
return sb.toString();
}
}
package i_introduction._1_Java_To_Kotlin_Converter;
import util.JavaCode;
import kotlin.collections.Collection;
class JavaCode1 : JavaCode() {
fun task1(collection : Collection<Int>) : String {
val sb = StringBuilder()
sb.append("{")
val iterator = collection.iterator()
while (iterator.hasNext()) {
val element = iterator.next()
sb.append(element)
if (iterator.hasNext()) {
sb.append(", ")
}
}
sb.append("}")
return sb.toString()
}
}
The first thing you'll notice is that the java.util.Collection is gone since Kotlin has its' own implementation and is imported by default.
Next is the code's lack of Visibility Modifiers. This is because everything is public by default. In addition to public there are protected, private and internal which work the same .NETs modifiers.
The next change is the variables, you don't need to define the type before the variable... you just define val for read-only variables or var for mutable variables. This is similar to C#s var keyword.
The final change is the lack of semicolons. This doesn't mean Kotlin doesn't have them, it means they are optional. You can add them as if it was Java or C# with no issue, it is you don't need them unless you are doing something confusing for the compiler.
SFTPK: Red/Black Trees
This post is one in a series of stuff formally trained programmers know – the rest of the series can be found in the series index.
Building off of the Binary Search Tree, we get the red/black tree which aims to solve the problem that a BST can become unbalanced.
The short version of a red/black tree is that is a BST with a set of rules that help us keep it performing well.
Thinking back to the BST, when we are doing the inserts and deletes at some point we need to rebalance the tree to ensure we keep that sweet O(log n) performance for searching. When is the right time to do that rebalancing?
A red/black tree extends a BST by adding one bit of information to each node; for those keeping track, our node now has the data, a key and a flag.
The flag is either red/black and there are 7 rules a BST (there are 5 official ones that relate to the colours, the first 5 below, but there are two more for the BST itself):
- Each node is either red or black
- The root node is black
- All leaves are black. These leaves can be the null points off of a node or they can be explicit nodes.
- A red node can only have black children
- Any path from a node to the leaves contains the same number of black nodes
- New nodes added are always Red.
- If the depth of a path is more than twice that of the shorted path we need to do a rotation.
So with these rules, insert & delete get more complex because you need to check these rules and, if the rules do not work you start to correct the issue. What is great with this is that because of the rules you become really efficient at correcting the problems.
So let's look at a really simple BST:

Next, let's make it a red/black tree following our rules above. I am also going to add the leave nodes in this image to help explain it but will take them out the remaining ones.

Note:
- that from the root node you need to go through 1 black node to reach a leaf node regardless of path.
- All red nodes only have black children.
- A black node can have black children.
Now we are going to add a node with value 11. It is added in the correct place and as a red node.
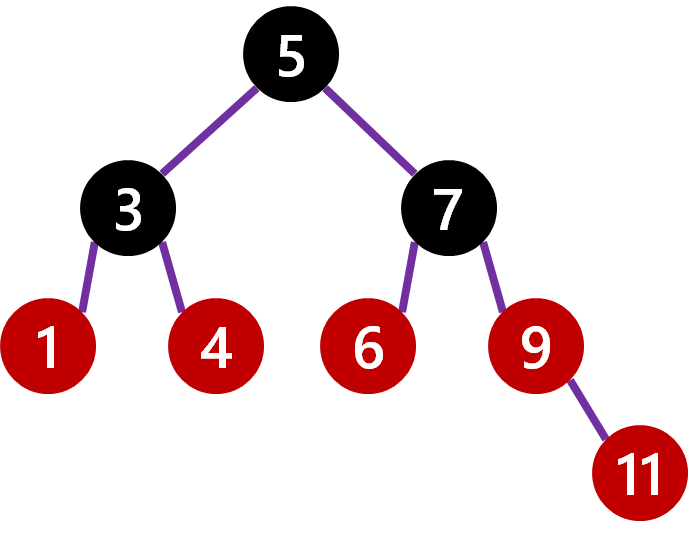
However 9 is red and has a red child, so we need to trigger a repaint of it to black. That causes a new issue, that from the root node to the leaves you may go through 1 black node by going left or 2 black nodes by going right, so we need to paint the parent of 9 (i.e. 7) to red. Lastly, since 7 is now red, 6 must be repainted to black. Finally, we have a correct red/black tree again.
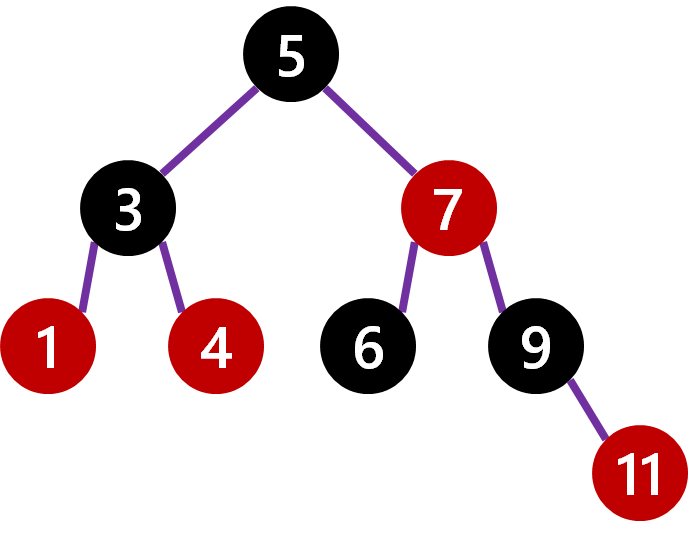
Lastly let us add 10, which goes under 11. Immediately we note that the length from 5 to the leaf of 10 is 4 steps, while the shortest path (the left side) is 2. We know we need to do a rotation.
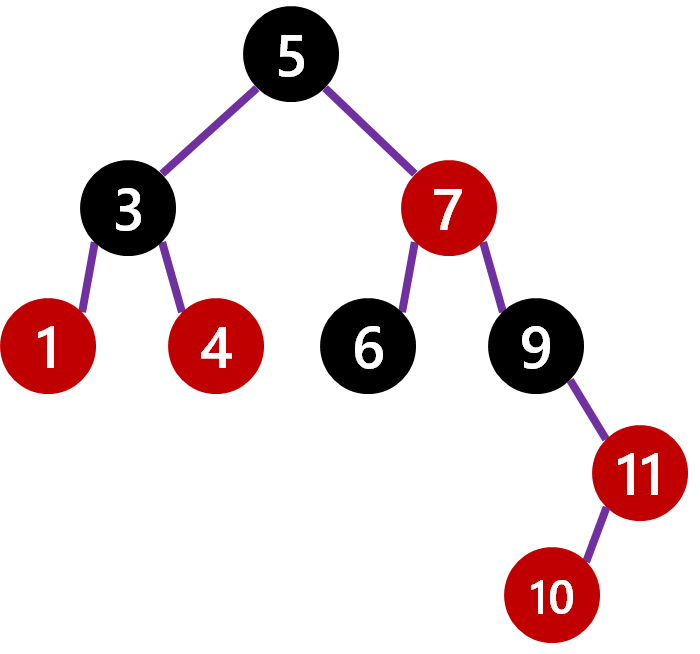
The rotation is easy, we take the child of the longer side (i.e. 7) and make it root and make the original root (i.e. 5) a child of it. Since 7 has two children already (5 and 9), it's original child 6 moves to under 5. Next, we just trigger a repaint, starting with the fact 7 needs to be black and you end up with the following:
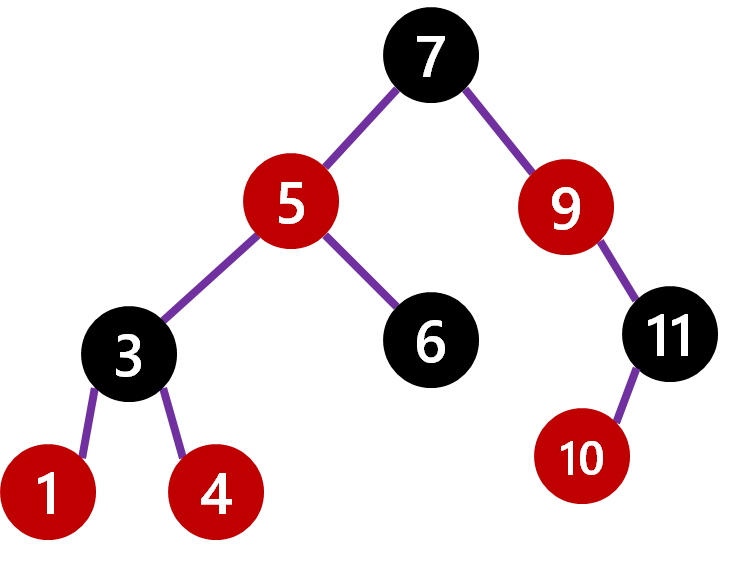
This might seem really expensive to do, but since you are just changing pointers and only a few the performance of the insert becomes also O(log n).
Implementations
Unfortunately, neither Java, .NET nor JavaScript has out of the box implementations but there are plenty of ones available if you search for it.
Learning Kotlin: Hello World
- The code being referenced.
- This is the 1st post in a multipart series.
If you want to read more, see our series index
So let's start with line one: package i_introduction._0_Hello_World
In Kotlin package is just the same as a package in Java or Namespaces in .NET. There is no link between package name and the filesystem.
Next up is imports:
import util.TODO
import util.doc0
Imports are the same as import in Java and Using in C#. Kotlin does import a number of packages by default:
- kotlin.*
- kotlin.annotation.*
- kotlin.collections.*
- kotlin.comparisons.* (since 1.1)
- kotlin.io.*
- kotlin.ranges.*
- kotlin.sequences.*
- kotlin.text.*
Next up is our first function defination fun todoTask0(): Nothing = ...
We use the fun keyword to state it is a function, followed by the function name todoTask0 and the parameters... in this case, that is empty.
The function returns Nothing though that isn't specifically required as the compiler can infer the return type.
This is a single statement function so it ends with an equal sign.
The next function is a little different
fun task0(): String {
return todoTask0()
}
The second function returns a String and is not a single statement function.
So how do we solve this Koan?
fun task0(): String {
return "OK"
}
Learning Kotlin: Introduction
I have recently decided to start to learn Kotlin, and have started with the Koans.
Koans are simple unit tests which help ease you into learning a new language.
The first step was setting this up, in Windows and VSCode... cause for some reason I hate myself that much.
Requirements
- Install Java SDK
- Install the Java Extension Pack for VSCode
- Install the Kotlin Language Extension for VSCode
Using
So I am using VSCode as the editor and then the command line to run the unit tests.
Parts
Since this will be ongoing, I am going to break it into a number of parts, listed below (this list will be updated over time):
- Hello World
- Java To Kotlin Converter
- Named Arguments
- Default Arguments
- Lambdas
- String Templates
- Data Classes
- Nullable Types
- Smart Casting
- Extension Functions and Extensions On Collections
- Object Expressions and SAM Conversions
- Kotlin's Elvis Operator
- Return when
- The awesome that is the backtick
- Collections
- It is a thing
- Operators
- Operators don't need to mean one thing
- Destructuring
- For Loop
- Invoke
- Looking at the In Operator & Contains
- The .. operator
- Todo
- By
- The lazy delegate
- The Observable Delegate (with a slight detour on reference functions)
- The map delegate
- The vetoable delegate
- The notnull delegate and lateinit
Quick tip: Column display
When you work with delimited data (CSV, TSV etc...) it can be a pain to just see the data in a nice way, for example, this data:
cat people-example.csv.txt First Name,Last Name,Country,age "Bob","Smith","United States",24 "Alice","Williams","Canada",23 "Malcolm","Jone","England",22 "Felix","Brown","USA",23 "Alex","Cooper","Poland",23 "Tod","Campbell","United States",22 "Derek","Ward","Switzerland",25
With Unix like OSs, you can use the column command to format the layout; for example:
column -t -s',' people-example.csv.txt First Name Last Name Country age "Bob" "Smith" "United States" 24 "Alice" "Williams" "Canada" 23 "Malcolm" "Jone" "England" 22 "Felix" "Brown" "USA" 23 "Alex" "Cooper" "Poland" 23 "Tod" "Campbell" "United States" 22 "Derek" "Ward" "Switzerland" 25
With Windows, you can use Import-CSV and Format-Table in PowerShell:
Import-Csv .\people-example.csv.txt | Format-Table
First Name Last Name Country age
Bob Smith United States 24 Alice Williams Canada 23 Malcolm Jone England 22 Felix Brown USA 23 Alex Cooper Poland 23 Tod Campbell United States 22 Derek Ward Switzerland 25
SFTPK: Binary Search Tree
This post is one in a series of stuff formally trained programmers know – the rest of the series can be found in the series index.
Binary Search Tree
In the previous post, we covered a Binary Tree, which is about the shape of storing the data. The Binary Search Tree (BST) is a further enhancement to that structure.
The first important change is that the data we are storing needs a key; if we have a basic type like a string or number then the value itself can be the key and if we have a more complex class, then we need to define a key in that structure or we need to build a unique key for each item.
The second change is a way to compare those keys which is crucial for the performance of the data structure. Numbers are easiest since we can easily compare which is larger and smaller.
The third and final change is the way we store the items; the left node's key will always be smaller than the parent nodes key and the right node's key will be larger than the parent node.
As an example, here is a BST using just numbers as keys:
 {height=300}
{height=300}
Note that all nodes to the left are smaller than their parent and all parents above that.
Why?
So, why should we care about a BST? We should care because searching is really performant in it as each time you move a depth down, you eliminate approximately 50% of the potential nodes.
So, for example, if we wanted to find the item in our example with the key 66, we could start at the root (50) and move right. At that point, we have eliminated 8 possible nodes immediately. The next is to the left from the node with the 70 (total possible nodes removed 12). Next is to the right of the node with the value of 65, and then to 66 to the left of 67. So we found the node with 5 steps.
Going to Big O Notation, this means we achieved a performance of close to O(log n). It is possible to have a worst case of O(n), when the tree is not Optimal or Unbalanced.
Balanced versus Unbalanced
In the above example we have a binary search tree which is Optimal, i.e. it has the lowest depth needed. Below we can see a totally valid BST; Each child node is to the right of the parent because it is bigger than the parent.
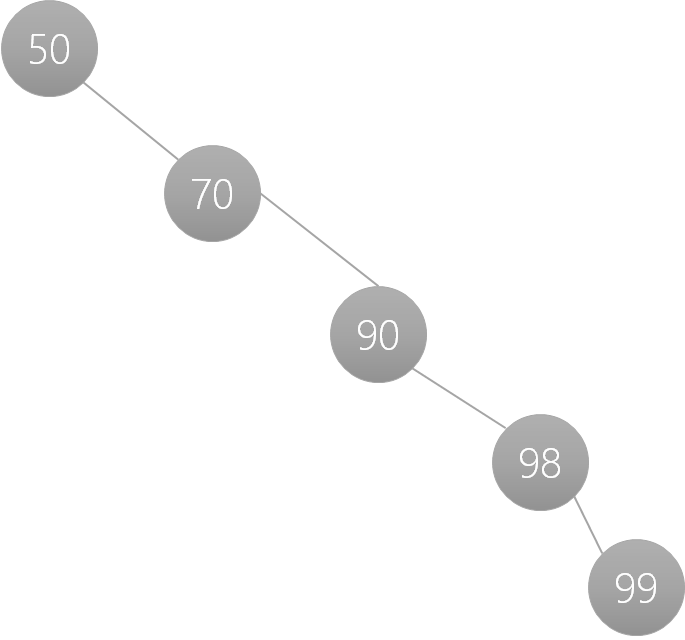 {height=300}
{height=300}
This, however, will result in a O(n) search performance which is not ideal. The solution is to rebalance the BST and for our example above we can end up with multiple end states (I'll show two below). The key takeaway is that we go from a depth of 5 to a depth of 3.
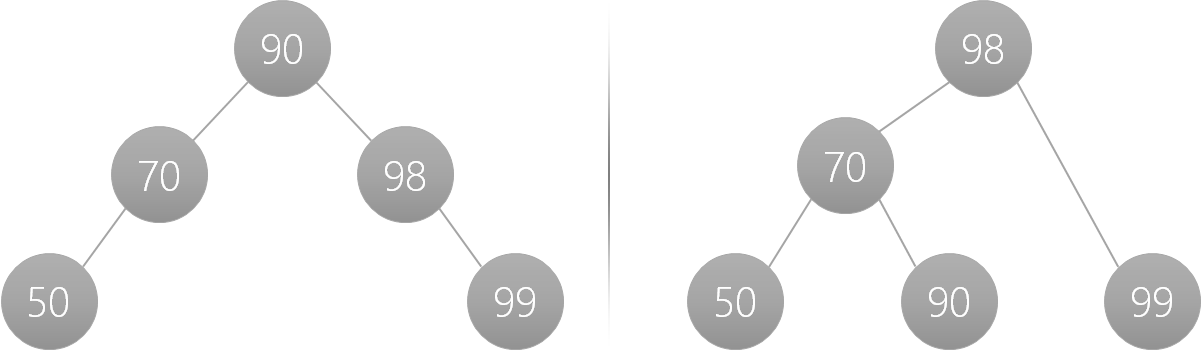 {height=300}
{height=300}
#Implementations .NET has a built-in implementation with SortedDictionary. Unfortunately, nothing exists out of the box for this in JavaScript or Java.