Trying out DenoDeploy Early Access
I have been using DenoDeploy for my experiments and toys recently, and been wowed by it. Recently they have announced their version 2 is coming, and you can try it out in early access now: https://deno.com/deploy
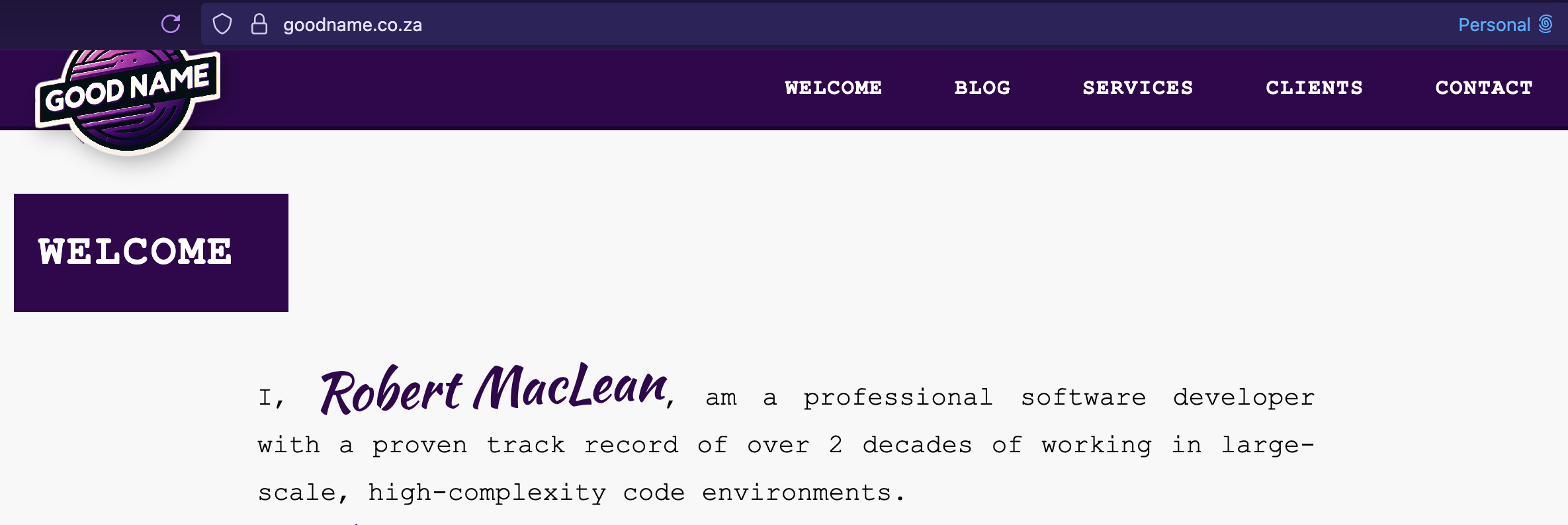
I wanted to try this and felt that after a year, it was a good time to rebuild the website for my sole proprietorship, https://www.goodname.co.za. Last year when I launched it, I hosted it on my main (expensive) hosting provider where I run this and used Drupal as a system for it... all because it was quick to get going.
In a year, I did no updates and spent way too long updating dependencies I didn't need... so why not use something new with DenoDeploy EA? And what could I not do before... run static HTML content! Yeah, DenoDeploy now lets that work and since I can put together HTML/CSS/JS quickly... it makes it really solid. It also means I can use my normal dev tools and push updates via GitHub.
I don't have much more to say, because DenoDeploy EA just worked; it was easy to configure (just connect to GitHub), link the domain via DNS and BOOM! It is running! It is amazing. I am very excited to see what is coming from that in the future.
If you are looking for a place to run TypeScript, JavaScript, or static content... you owe it to yourself (and your wallet) to check it out.
Bring your Google calendar into a spreadsheet
When it comes to spreadsheets, Excel kicks ass, like it is massively more powerful than anything else out there, but I have recently had to pull Google Calendar info into a spreadsheet and rather than manual capturing it, I found that Sheets from Google with the App Script is really powerful thanks to the unified Google experience.
To bring in the info, I followed the following steps.
- Create a new spreadsheet (I used the awesome https://sheets.new url to do that)
- In the spreadsheet, add your start and end dates for the range you want to import. I put start in A1 and end in B1
- Click extensions → App Scripts
- In the Code.gs file, drop the following code in
// Configuration constants
// change these as needed
const START_DATE_CELL = 'A1';
const END_DATE_CELL = 'B1';
const HEADER_ROW = 3;
const HEADER_COL = 2;
// do not change these
const DATA_START_ROW = HEADER_ROW + 1;
const NUM_COLS = 3;
function calendar_update() {
//your calendar email address here
var mycal = Session.getActiveUser().getEmail();
var cal = CalendarApp.getCalendarById(mycal);
var sheet = SpreadsheetApp.getActiveSheet();
// Clear existing data rows
var currentRow = DATA_START_ROW;
while (true) {
var checkRange = sheet.getRange(currentRow, HEADER_COL, 1, NUM_COLS);
var values = checkRange.getValues()[0];
var hasData = values.some(cell => cell !== '' && cell !== null && cell !== undefined);
if (!hasData) {
break;
}
checkRange.clearContent();
currentRow++;
}
//put dates here
var events = cal.getEvents(
sheet.getRange(START_DATE_CELL).getValue(),
sheet.getRange(END_DATE_CELL).getValue(),
{ search: '-project123' },
);
var header = [['Date', 'Event Title', 'Duration']];
var range = sheet.getRange(HEADER_ROW, HEADER_COL, 1, NUM_COLS);
range.setValues(header);
var rowIndex = DATA_START_ROW;
for (const event of events) {
if (event.getTitle() === 'Busy' || event.getTitle() === 'WFH' || event.getMyStatus() === CalendarApp.GuestStatus.NO) {
continue;
}
var duration = (event.getEndTime() - event.getStartTime()) / 3600000
var details = [[event.getStartTime(), event.getTitle(), duration]];
var range = sheet.getRange(rowIndex, HEADER_COL, 1, 3);
range.setValues(details);
rowIndex++;
}
}
- Set the config at the top of the script and hit save
const START_DATE_CELL = 'A1'; // this is where you specified the inclusive start date to pull from
const END_DATE_CELL = 'B1'; // this is where you specified the exclusive end date to pull to
const HEADER_ROW = 3; // the row for where the header for the table will be
const HEADER_COL = 1; // this is the column where the first part of the header is A = 1, B = 2 etc...
- Save and run... you will be asked for auth, this is a one time approval;
- The content will be in the sheet now! But let's make it easy top update
- Go to Insert → Drawing, and draw a button or icon and hit insert
- On the button, click the 3 dots and select Assign Script
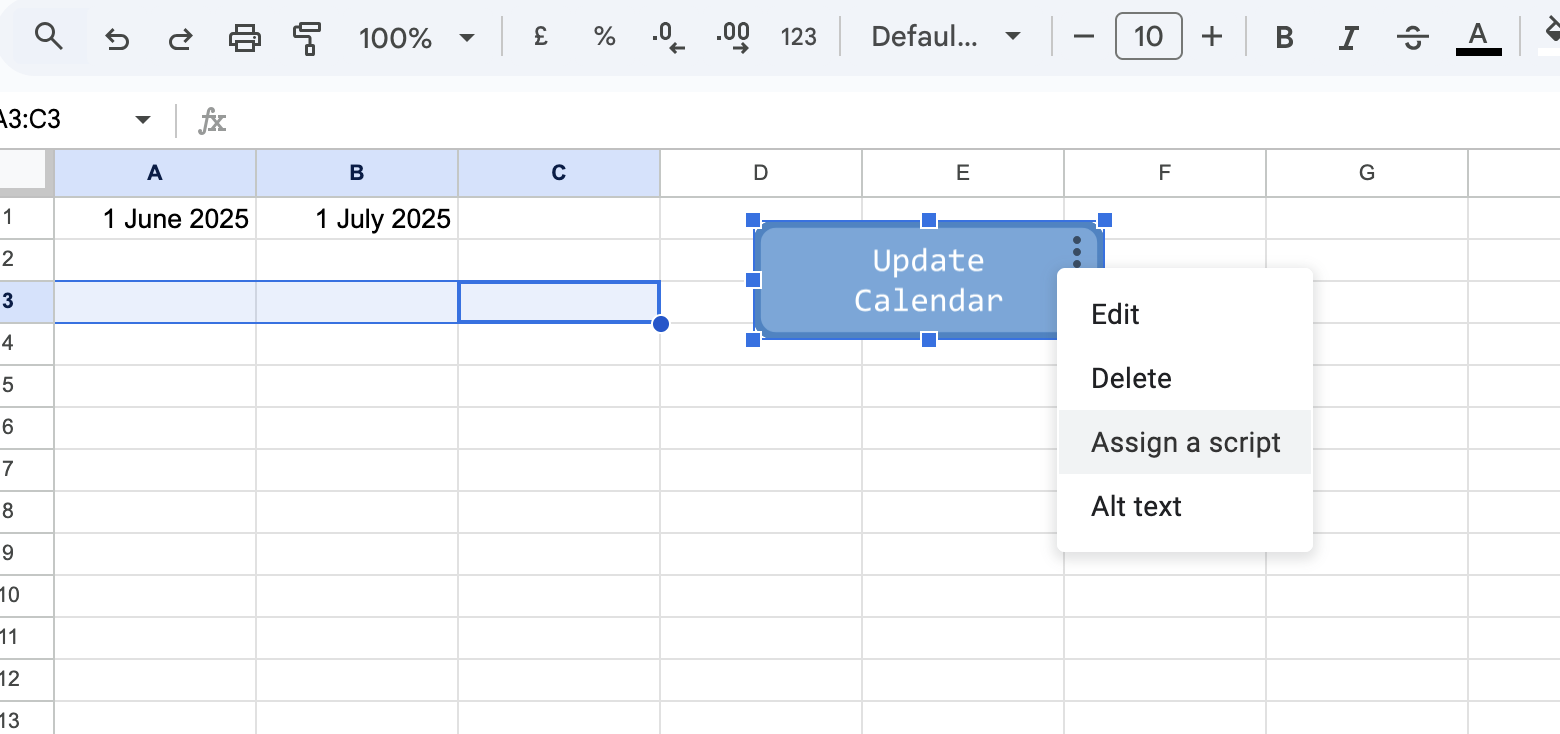
- For which script do you want to assign, put in
calendar_updateand click Ok.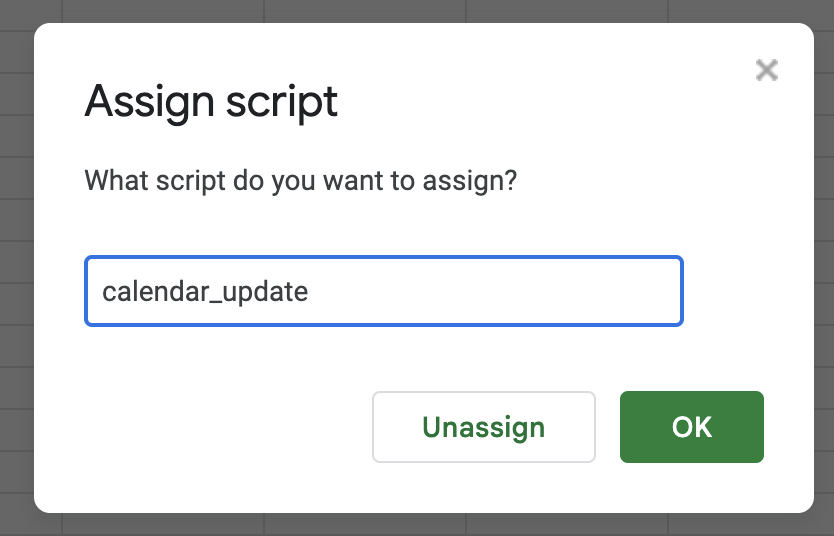 Now you can click that button at any time and it will update
Now you can click that button at any time and it will update
And as a final awesome trick, you may wish to convert something like 0.25 to a human-readable 15 minutes? I use the formula =TEXT(<VALUE>,"[h] \h\o\u\r\s m \m\i\n\u\t\e\s")
My Secret Weapon: Single-Letter Git Aliases

Today I want to share my favourite Git aliases that I've built up over the years. If you haven't heard of a Git alias, it's basically a way to add your own custom commands to Git. Think of it as a personal shortcut for frequently used Git operations (you can check out the official docs here for the technical deep dive).
You could add these to your shell directly, and they'd work pretty similarly. But for me, that requirement of still having to type git first really keeps them nicely ring-fenced. It helps keep my mental space focused just on Git commands. Plus, since I use these constantly, they're all single-letter commands. If you're doing everything on the shell, you might run out of good single letters (depending on your shell, you've only got so many!). Here, I still have a limit, but it's focused specifically on Git commands, so I'm not going to hit it anytime soon.
My Go-To: git u (Update Branch)
First up is u. This one is for updating my branch. Most days, before I even start coding, I want to update my feature branch to main. I also like to do a bit of clean-up to keep Git per formant and my local repo tidy. Man, this used to be a bunch of things I had to remember to do:
-
Switch to
main... except it might also bemaster,release, orstaging. I bounce between multiple teams and clients, and remembering which one is which each time can be tiring. -
Run
fetch --pruneto clean up any local branches that no longer exist on the remote. Keeps things neat! -
Pull the latest changes into my local
main. -
Run
maintenancefor performance goodness. - Switch back to my feature branch and merge those fresh changes across.
That's a lot of individual commands, right? Today, that's just git u. Internally, the alias looks like this:
alias.u=!git switch $(git symbolic-ref refs/remotes/origin/HEAD | sed 's@^refs/remotes/origin/@@') && git fetch --prune && git pull && git maintenance run && git switch - && git merge $(git symbolic-ref refs/remotes/origin/HEAD | sed 's@^refs/remotes/origin/@@')
Now, where this still messes up for me is on one client where their main is actually production, but their workflow dictates pulling from staging... so it's a bit weird. And then there's the classic rebase vs. merge debate. I landed on merge for this alias since it's often safer, but I do wonder if I could build a smarter system to try rebase, and if that has issues, then switch to merge. Food for thought!
Branching Out with git n (New Branch)
Next up is n. This one is for creating a new branch. Take everything from the u command above, except for the last step (merging back). Instead, I want to type in a new branch name, and it creates that new branch for me. That was super easy to integrate using read, and the final alias looks like this:
alias.n=!git switch $(git symbolic-ref refs/remotes/origin/HEAD | sed 's@^refs/remotes/origin/@@') && git fetch --prune && git pull && git maintenance run && read -p 'New branch name: ' branch && git switch -c $branch
And there you have it! These two aliases have saved me countless keystrokes and mental gymnastics over the years.
TIL: Tax is a asymptote
Tax is complicated, and we don't even have lunatic tariffs to worry about.
Often people talk about the fact we pay up to 45% tax in South Africa, but that is seldom true; in fact, mathematically it will never be true because tax is something called an asymptote. Even if you round up, you have to earn over R32.1 million a month, to get to 45% - something no-one (or very few people) will get close to.
I wanted to see and play with this, so I built taxreality.sadev.co.za this evening to play with the formula and visualise it.
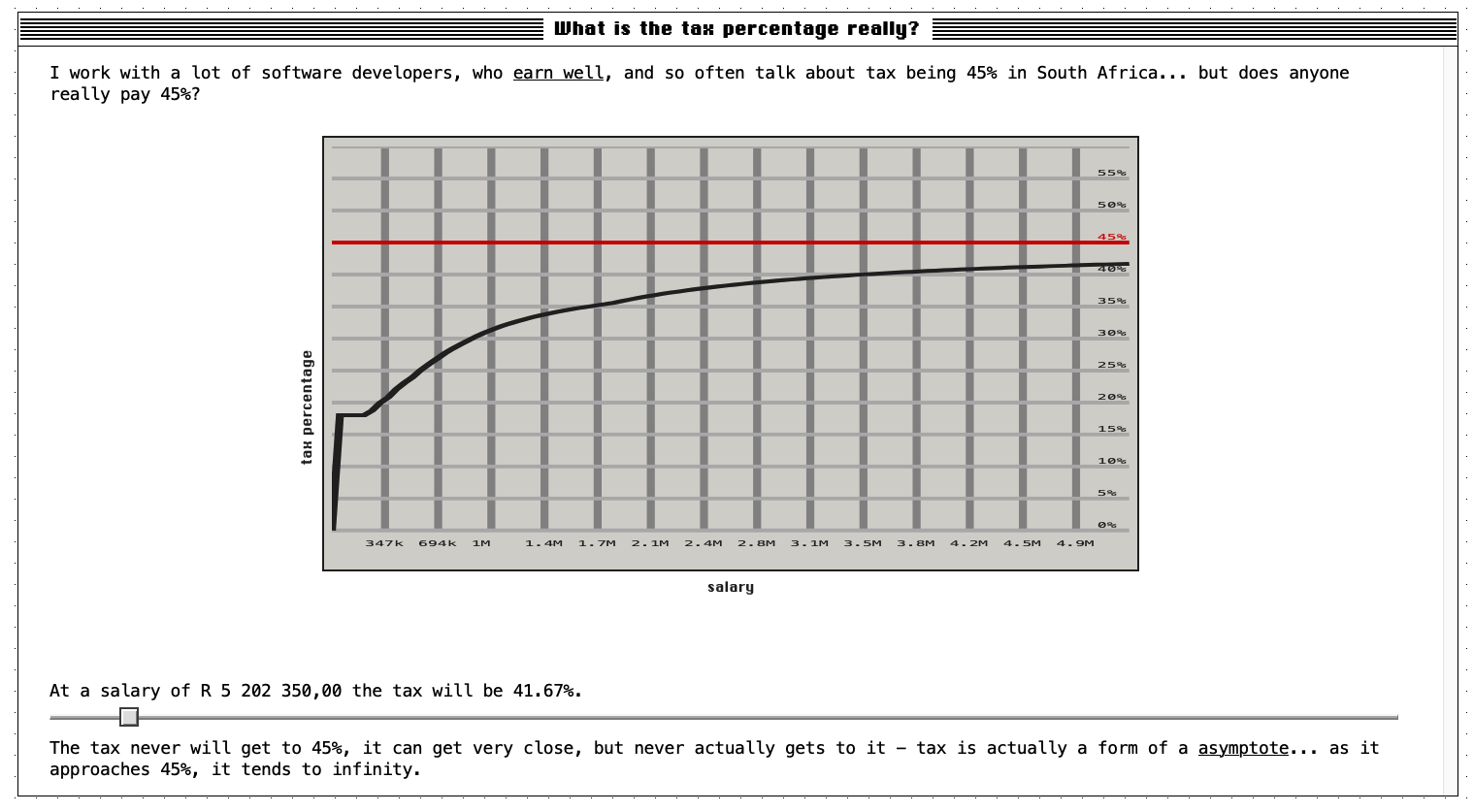
Like with my last project, it is built with Deno, Fresh and Deploy. In addition, I also made use of System.css for some of the styling and RealFaviconGenerator which is an amazing tool; it let me use a SVG and have it change to work with light and dark mode!
A holiday project with Deno 🦕, Fresh 🍋 , Deploy and Formula 1 🏎️

The project is up at: https://f1teams.sadev.co.za/
Yesterday was a public/bank holiday in South Africa, and that it gave me a chance to try to build something green fields in a day... but I also wanted to push some skills by doing some more work with Deno. Initially thought about building with Next, but I use that often... so thought I would try Fresh (the framework from Deno) and that naturally led to using Deploy, the hosting that Deno also offers.
But what to build? How about a simple website which shows the evolution of Formula 1 teams in time for the Grand Prix this weekend, so I can see what each team was called over time.
Building with Deno, was, as always, painless - native TypeScript support and the full tool chain was great. Only issue I had was that I want trailing commas on my JSONC data... but the formatter won't let that be (so very minor). Fresh was uneventful... honestly, if you know Next, getting up and running takes so little extra time and the structuring makes so much sense. Deploy was an absolute highlight though - an amazingly easy to deploy from GitHub service with very generous free tier. I am now thinking of how many ways I can make use of that.
From start to finish, it took about a half day... and this is using new technologies - this is an amazing stack for quick and professional development.
Two other different aspects I used:
-
When I started I hadn't planned on using Deploy, which has a free KV available and likely if I wouldn't use that if I had planned to use Deploy... but since I didn't I went with a static JSONC file and parsed it with JSONC-Parser. I absolutely love JSONC more than pure JSON... and the sooner we all move to it, the better.
-
I used no component library.... everything is "handcrafted" HTML and CSS. Not even something like SASS... I still think there is a use for component libraries in bigger systems, but modern HTML & CSS is so powerful that it is just wonderful to keep the size down (the whole website is 100Kb)
The more things change... the more they stay the same

DevFest 2024 - Slides and info about my CLI
 Today I presented at DevFest which was a great experience! A bunch of people wanted my slides/notes from my talk so they are available below.
Today I presented at DevFest which was a great experience! A bunch of people wanted my slides/notes from my talk so they are available below.
CLI Stack
Multiple people also asked about my CLI experience and what it is since it seems so powerful. My CLI stack is as follows:
- The terminal is Warp - I have written about it on my Newsletter
- The shell I use remains Fish which is easily the best switch if you coming to more shells from Windows, which is how I got to it, and after almost a decade... I still love it
- The prompt I use Starship. Warp has a lot of options but Starship can respond to your machine, and the folder to give even more power. Plus mine has the Pansexual Flag colours, which brings me so much joy.
- I make use of Fzy for CD autocompletion
14 things you need to be a successful software developer - Number 5 - Software development is not about coding

This is the first in the second act of the trio of sections that this series has, and it focuses on what it is like to be a software developer. When I first wrote this, I did it for a university talk and thought the advice on what it is really like to be a software developer might help the students understand what they will find and get successful faster. Since I have been consulting and speaking to many people, I have realised that there are developers at every level who do not know these things and some, especially very talented and senior, feel they are there to sit alone and churn out "perfect code"... and they are wrong.
If I were to distil what software development is about to a word, it is tradeoffs. We are always making tradeoffs, and in terms of what those trade-offs are, it is just 3 things: Capacity, Time and Features. Very simply, if you want to change one - you need to change at least one more of them and sometimes two others.
I have always liked visualising this as a semi-rigid triangle with each being a side of the triangle.
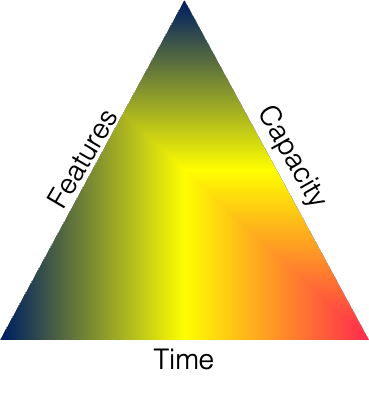
Time
The time aspect is probably the easiest to think about; it is how long it will take. This can be viewed as the whole project, but also can be viewed down to individual tasks.
Capacity
This used to be called People and Resources but we should always remember that People are not resources; and when we think of this as People or Resources we miss the nuance of this.
When working with this triangle and talking about the costs of a project, capacity often aligns nicely with people, so if you want to lower the costs this is an obvious one, that means you would need to increase time (i.e. how long it will take) or decrease features. Capacity though is not just about costs; for example, if you have a single developer you might feel you can move capacity... but it can be changed.
Are you context-switching a lot? That has an impact on capacity. Are they doing a lot of maintenance work? again, impacts capacity. Even the modern view that scrum has failed, is in part a realisation that the cost of scrum is directly on the capacity side without a greater or even equal impact on the time side.
Even how psychologically safe your environment impacts this because a higher-stress environment lowers the capacity for your people to deliver.
Features
Finally is features, this is not only what the software does but how it does it. Do we build a feature in a way that meets the needs now or also ones that we foresee coming in a feature months? Those are effectively two different sizes of the same thing; i.e. features is not one-to-one to the stories or epics in your backlog.
Features also incorporate quality, observability, and non-functional requirements (FYI Donald Graham's DevConf talk is a must-watch on non-functional requirements... so checkout the DevConf YouTube for when it comes out. A feature you create with shitty code versus great code has different sizes here.
Tradeoff
Now that we have the triangle and we understand the trade-off, it comes back to our initial rule that our job is not about coding. Yes, the triangle has aspects of coding but our goal is to ship a solution and to do that successfully, it is the identify what will impact the trade-offs, and find solutions to that. If you can do that, you will be way more of a successful developer and, importantly, the code you do write will be code that matters... not just a bunch of electrons sitting idle on a disk.
What can you control about this?
-
Avoid the "it's not my job" view, the goal is shipping software which is used. That is a team sport and if you can help achieve that but doing something outside your comfort zone, it is worth doing.
-
Finally, while remembering the triangle - also remember Hofstadter's Law: It always takes longer than you expect, even when you take into account Hofstadter's Law.
Escape Conf
 .
.
Last week I presented a session at Escape Conf on what is new and awesome in JavaScript development! It will be up on YouTube in the near future but for now, if you looking for the slides, notes or anything... you can grab it below!
14 things you need to be a successful software developer - Number 4 - Software systems are alive

The more I work with startups, the more I realise how important this rule is - it does define the difference between success and failure; very simply your software is alive and it is your job as a software developer to keep it alive.
This starts with your DevOps strategy, and investing into that. Having a build provides a heartbeat for the project and when a commit breaks the build... it is like a flat-lined heart. The code in your repo should always be ready to ship; that heartbeat is the sign that it is ok. The benefit of this is that it is the first step to continuous deployment which is the ideal goal.
Once you have software running, it is still your responsibility to keep it alive. Stats show that 80% of the software development cost is accrued while maintaining the software. This blows my mind if something costs R100 000 to build... it will cost R400 000 to maintain! So everything you can do to lower maintenance costs has MASSIVE benefits in terms of cost savings.
As such, I truly believe we need to change the view that software developers are builders and architects, and rather realise we are gardeners or farmers. We prep the fields, plant, collect data on the growth, adjust the fertilisers and eventually harvest... but that is not the end, we need to prepare the fields for the next season. The model matches how we work so well, and more importantly, reminds us of our responsibility to living systems.
So what can you do in your own life and team to improve this?
-
Ship early, ship often, and get feedback: The shorter your cycles of getting content out to your customers and users, the faster you will understand what works and what does not. We often think of this in the realm of shipping versions or deployments, but I have found that even testing benefits from this. Leaving testing to the end of a project is a way to slow it down. Start UAT in your second week and you'll find you will ship faster.
-
Focusing on maintenance is likely the best way to lower costs on a project. Anything you can do, from using services from your cloud provider to get better logs, more observability, and tools to help you debug and admin the system is going to help.
-
Finally, the more risky a thing is - the more often you should do it. We solve risk, not by red tape but by doing it more and solving the issues which come up.